
Die Ausgangslage
Im Frühjahr 2026 stand bei Eventlights.shop ein Systemwechsel (im Blog: Von Plentyshop zu Woocommerce) bevor: Das PlentyONE SaaS-ERP-System passte nicht mehr zum Geschäftsmodell und sollte in Rente geschickt werden. Monatliche Fixkosten sollten für das Alt-System natürlich keine mehr anfallen. Und so kommen wir zum Dilemma, das viele moderne Cloud-Software-Systeme mitbringen: Sobald man nicht mehr monatlich für die Software bezahlt, kann man sie auch nicht mehr nutzen, und die eigenen Daten sind über die Software nicht mehr zugänglich.
Bei ERP- oder Warenwirtschaft-Software bedeutet das: Wenn ein Stammkunde am Telefon ist und seine jährliche Bestellung aufgeben möchte, kann man nicht mehr einfach die letzten Aufträge ansehen und Artikel vielleicht direkt in einen neuen Auftrag kopieren. Wenn eine Reklamation oder Retoure im Kundenservice landet, sind die Mitarbeiter dort „blind“, da sie nicht wie gewohnt den Auftrag im System suchen können.
Weitere Folgen einer Cloud-Software-Kündigung zeigen sich erst mit der Zeit: Der Einkauf könnte Probleme haben, die optimalen Bestellmengen festzulegen, wenn die Verkaufsstatistiken auf Artikelebene nicht mehr wie gewohnt verfügbar sind. Für Sortimentsentscheidungen könnten ebenso Daten fehlen. Und wenn am Jahresende die in Verkehr gebrachten Verpackungsmengen gemeldet werden sollen, kann es ebenso ein böses Erwachen geben.
Während man Stammdaten wie Kundendaten und Artikeldaten noch relativ einfach exportieren und in neue Systeme übernehmen kann, ist das bei Auftragsdaten und den darauf aufbauenden Statistiken schwieriger.
Daten exportieren: die Möglichkeiten
PlentyONE bietet verschiedene Methoden, Daten aus dem System zu holen:
Katalog-Export
Über diese Export-Funktion lassen sich Aufträge, Kontakte und andere Daten als CSV-Dateien exportieren. Dazu muss man zuerst ein Katalog-Exportformat konfigurieren, was bei vielen Datenfeldern komplex sein kann. Wenn man den Export durchführen möchte, stößt man auf Limits – wer die Auftragsdaten von einigen Jahren exportieren will, muss zig separate Exports durchführen. Die Export-Dateien müssten dann zusammengefügt und nutzbar gemacht werden.
REST-API mit eigenem Script
Eine weitere Option ist die Daten-Abfrage über ein Script, das sich bei der API anmeldet und alle Aufträge seitenweise abruft. Das wäre machbar, aber das passende Script muss auch programmiert werden, und die heruntergeladenen Daten müssen lokal gespeichert und zugänglich gemacht werden. Bevor ich diese Möglichkeit weiter verfolgt habe, kam eine andere Entdeckung dazwischen.
Die Entdeckung: Backups der SQL-Datenbank
Ich wusste, dass PlentyONE Backups zum Download bereitstellt – aber als langjähriger Kunde kannte ich auch den Haken bei diesen Backups: PlentyONE-Datenbank-Dumps enthalten (Stand April 2026) keine Tabellen-Definitionen – also keine Beschreibung, welche Spalte einer Tabelle wofür steht. Damit kann man mit dem Backup zwar ein PlentyONE-System wiederherstellen – aber die Daten nicht so einfach in einem anderen System nutzen.
Im Gespräch mit dem KI-Assistenten Claude entstand dann die Idee: Man könnte doch versuchen, die verborgene Datenstruktur zu entschlüsseln und die fehlenden Informationen so zu ergänzen.
Ich habe die aktuelle Backup-Datei heruntergeladen, etwa 90 MB als komprimierte .sql.gz-Datei. Entpackt ergab das 810 MB, eine Textdatei mit etwa 5 Millionen Zeilen, die alle Daten meines PlentyONE-Systems enthält. Bei anderen Systemen kann die Datenmenge stark abweichen.
Welche Tabellen stecken im Datenbank-Dump?
Der erste Schritt war eine Inventur: Welche Tabellen sind überhaupt enthalten? Claude hat einen passenden Linux-Shell-Befehl bereitgestellt, um die Tabellennamen aus der .sql-Datei auszulesen:
user@rechner:~$ grep -oP "INSERT INTO \`\K[^\`]+" backup.sql | sort -u
plenty_account
plenty_account_address
plenty_account_contact
plenty_article
plenty_article_description
plenty_item_variation_base
plenty_order_main
plenty_order_item
plenty_order_amount
plenty_order_amount_vat
...Das Ergebnis: 426 Tabellen, darunter diese Kernbereiche:
- Aufträge:
plenty_order_main,plenty_order_item,plenty_order_amount,plenty_order_amount_vat,plenty_order_property,plenty_order_date - Adressen:
plenty_account_address,plenty_account_address_option,plenty_account_address_order_relation - Kunden:
plenty_account_contact,plenty_account_contact_option,plenty_account - Artikel:
plenty_article,plenty_article_description,plenty_item_variation_base,plenty_item_variation_barcode - Zahlungen:
plenty_pay,plenty_pay_order_relation - Dokumente:
plenty_document,plenty_documents
Dazu spezialisierte Tabellen wie plenty_amazon_order_transaction für die Verbindung zwischen Amazon-Bestellnummern und Auftrags-IDs, oder plenty_comment für interne Notizen zu Aufträgen.
Das Zielformat: SQLite
Bevor ich etwas mit den Daten machen konnte, musste ich sie zuerst in einer passenden neuen Datenbank speichern. SQLite war für meinen Zweck (lokales Archiv) passend: Die gesamte Datenbank steckt in einer einzigen .db-Datei, sie lässt sich mit einem SQLite-Client wie DBeaver öffnen, und 78.000 Aufträge sind für SQLite eine triviale Größenordnung.
Für Firmen, in denen mehrere Mitarbeiter gleichzeitig auf die Daten zugreifen müssen, eignet sich eine MySQL-Datenbank, die auf einem Server läuft, besser.
Spalten ohne Namen
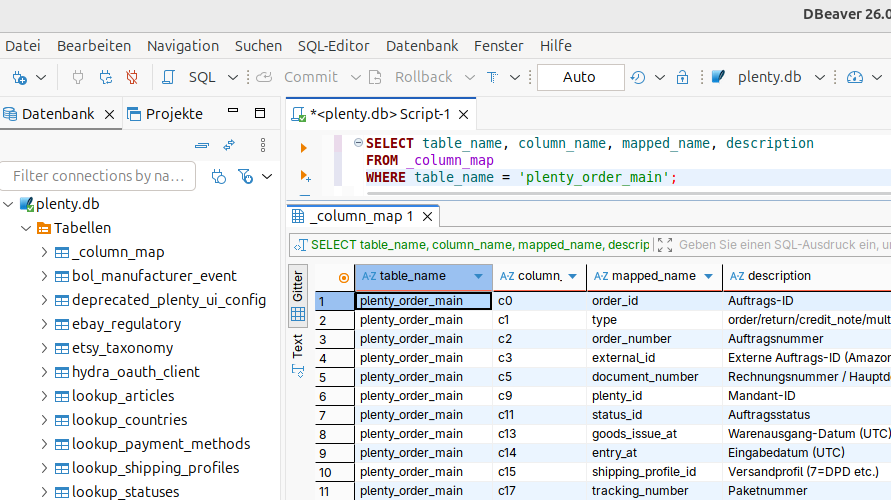
Claude stellte ein Script bereit, das alle Daten aus dem Backup in eine SQLite-Datenbank schreibt. Nutzbar war diese Datenbank aber noch nicht: Weil im Backup die Tabellen-Definitionen fehlen, sind beim Import auch keine Spaltennamen bekannt. Das Script legt die Tabellen deshalb mit durchnummerierten Platzhalter-Spalten an – c0, c1, c2 und so fort. Die Daten stehen also vollständig in der Datenbank, aber welche Spalte das Auftragsdatum enthält, welche den Bruttobetrag und welche die Versandart, war zunächst offen.
Der Schlüssel für die Zuordnung war ein einzelner Auftrag: Ich habe die Datenfelder im Plenty-Backend mit den Daten in der Datenbank abgeglichen und konnte so viele Spalten zuordnen.
Für manche Spalten brauchte ich zusätzliche Daten aus dem Plenty-Backend: die Liste der Zahlungsarten, die Status-Liste, die Versandprofile. Erst damit ließ sich festlegen, was bestimmte Zahlen bei einem Auftrag tatsächlich bedeuten – dass eine 7 als Status für einen abgeschlossenen Auftrag steht oder eine 22 als Versandprofil für einen bestimmten Dienstleister.
Tücken im Datenmodell
Beim Durcharbeiten zeigte sich, dass die Daten ein paar Eigenheiten haben, die man kennen muss.
Der Bruttobetrag eines Auftrags wird an zwei Stellen geführt: in der Haupttabelle plenty_order_main und in einer eigenen Betragstabelle plenty_order_amount. In meinem Datenbestand verschob sich das ab 2021: Bei älteren Aufträgen steht der Betrag in beiden Tabellen, danach nur noch in der Betragstabelle. Für eine vollständige Umsatzauswertung ist deshalb die Betragstabelle die verlässliche Quelle.
Etwas kniffliger war der Vertriebskanal. Plenty erfasst ihn über ein Referrer-Feld, das über die Jahre allerdings stark ausdifferenziert wurde: Aus anfangs wenigen Einträgen wurden mit der Zeit hunderte, Marktplätze wurden in viele Unterkanäle aufgeteilt (Amazon DE, FR, IT, FBA …), und die IDs änderten sich. Eine saubere Zuordnung auf wenige Hauptkanäle wäre damit aufwändig geworden. Für meinen Zweck war die Rechnungs-E-Mail-Adresse der einfachere Weg: Amazon verwendet Adressen nach dem Muster @marketplace.amazon.*, eBay nutzt @members.ebay.*. Über die E-Mail-Domain ließ sich der Kanal bei meinen Aufträgen ausreichend genau bestimmen.
Das fertige Script
Diese Erkenntnisse sind nach und nach in drei Python-Scripts geflossen, die ich in Zusammenarbeit mit Claude Schritt für Schritt verbessert habe: eines für den Import, eines für die Zuordnung der Spaltennamen, eines für die Kanalzuordnung. Für die Veröffentlichung habe ich sie zu einem einzigen Script zusammengeführt. So genügt ein Aufruf, statt drei Scripts nacheinander zu starten:
user@rechner:~$ python3 plenty_to_sqlite.py backup.sql
SQL-Datei: backup.sql (810 MB)
Zieldatenbank: plenty.db
Schritt 1: Tabellen importieren...
100% | 79s | 426 Tabellen | 5.423.266 Zeilen
Schritt 2: Kanal-Zuordnung pro Auftrag...
Schritt 3: Lookup-Tabellen erstellen...
Schritt 4: Views und Indizes erstellen...
Fertig. Datenbank: plenty.db (596.2 MB)Das Script läuft komplett lokal – die Geschäftsdaten verlassen den Rechner nicht. Nach gut einer Minute liegt eine SQLite-Datei von knapp 600 MB vor, die alle 426 Tabellen enthält und in der die wichtigsten Daten über lesbare Views (Aufträge, Positionen, Kunden, Umsatzstatistiken) abfragbar sind.
Das vollständige Script plenty_to_sqlite.py liegt im Repository auf Codeberg. Es ist auf meine eigenen PlentyONE-Daten abgestimmt – Spaltenpositionen und IDs können bei anderen Systemen abweichen und müssen angepasst werden.
Die Daten zugänglich machen
Nach diesen Anpassungen liegt eine Datenbank vor, in der alle zentralen Informationen abfragbar sind. Aber wie kann man darauf zugreifen? Für mich haben sich zwei Werkzeuge als sinnvolle Kombination herausgestellt: ein Datenbank-Tool wie DBeaver für Statistiken und Ad-hoc-Analysen, und ein leichtgewichtiges Web-Interface für die schnelle Suche im Alltag.
Der schnelle Weg: DBeaver mit einer Abfragen-Sammlung
DBeaver öffnet SQLite-Datenbanken direkt, zeigt Tabellen und Inhalte an, und führt Abfragen aus. Das Script legt fertige Views mit lesbaren Spaltennamen an, sodass man nicht mehr mit kryptischen Spaltennummern hantieren muss.
Eine Bestseller-Auswertung sieht zum Beispiel so aus:
--- ## Top-30 Bestseller nach Umsatz (alle Kanaele)
SELECT item_name AS artikel, channel AS kanal,
total_quantity AS menge, total_gross_revenue AS umsatz_brutto
FROM v_stats_top_products2
ORDER BY total_gross_revenue DESC
LIMIT 30;Eine Sammlung mit über 20 Beispiel-Abfragen liegt im Repository auf Codeberg. Sie deckt typische Fragen ab: Umsätze pro Jahr und Kanal, Bestseller-Listen, durchschnittliche Auftragswerte, die Suche nach einzelnen Aufträgen und Kunden, Zahlungsarten-Auswertung und Auftragsstatus.
Bequemer: ein lokaler Webserver
Für die alltägliche Suche – Kunde ruft an, fragt nach einer Bestellung – ist DBeaver zu unhandlich. Hier braucht man ein Werkzeug, das so einfach zu bedienen ist wie ein ERP-System.
Die Lösung ist ein Python-Script, das einen lokalen Webserver startet. Es wird im Terminal gestartet:user@rechner:~$ python3 plenty_search.py
Die Anwendung wird dann im Browser geöffnet: http://localhost:8080.
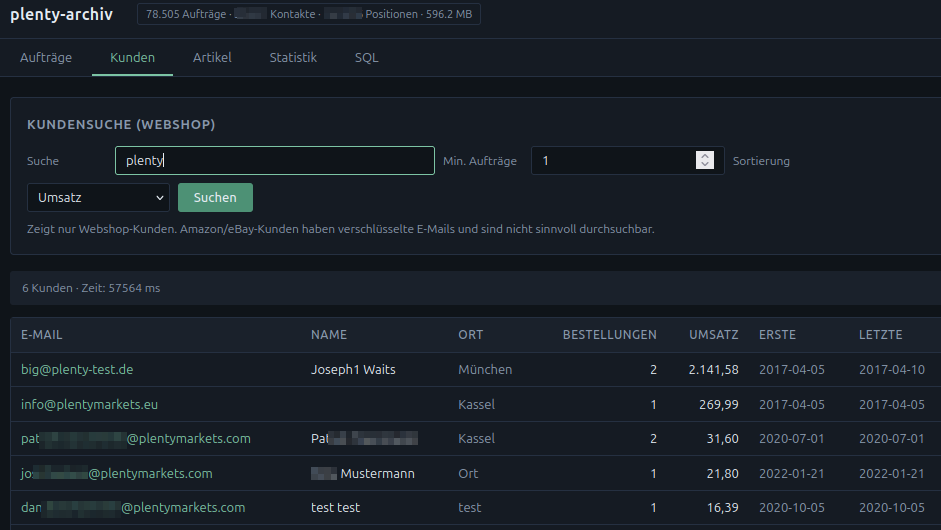
Die Oberfläche ist in mehrere Bereiche gegliedert: Aufträge, Kunden, Artikel, Statistik und eine SQL-Ansicht für eigene Abfragen. Die Kundensuche akzeptiert beliebige Eingaben und sucht parallel über mehrere Felder – E-Mail, Name und Ort. Das Ergebnis lässt sich nach Umsatz sortieren. Eine Eingabe wie plenty findet so alle passenden Kunden samt Bestellzahl, Gesamtumsatz und dem Zeitraum von der ersten bis zur letzten Bestellung.
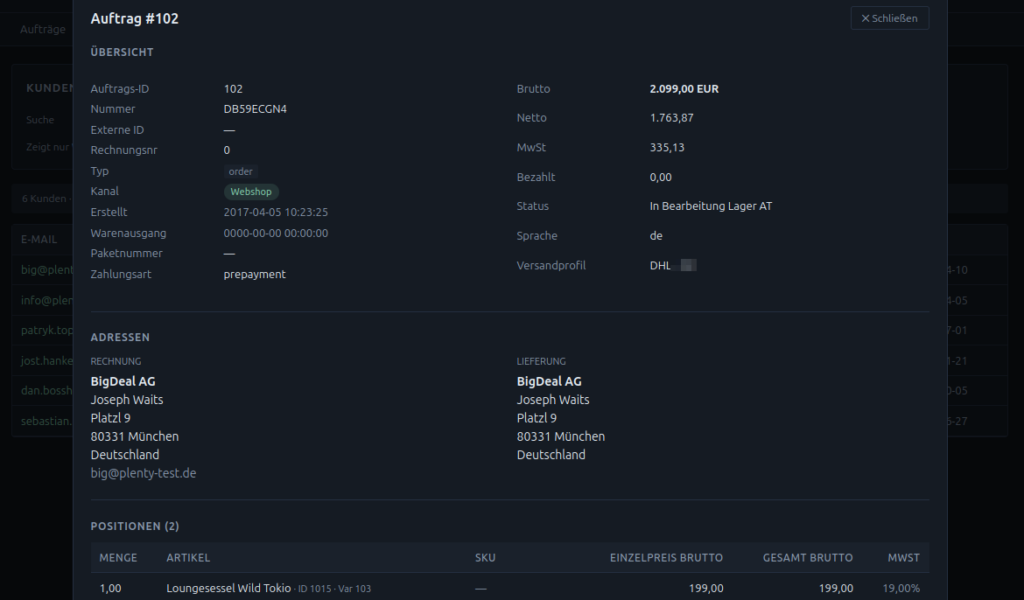
Die Auftragssuche funktioniert nach demselben Prinzip und findet eine Eingabe in mehreren Feldern gleichzeitig: Auftrags-ID, Auftragsnummer, Rechnungsnummer, Tracking-Nummer, Kundenname, E-Mail, externe ID (Amazon-Bestellnummer). Eine Eingabe wie 78712 führt direkt zum Auftrag.
Klickt man einen Treffer an, öffnet sich die Detailansicht: Auftragskopf mit Status, Datum, Kanal, Beträgen. Rechnungs- und Lieferadresse. Alle Positionen mit Artikelname, Menge und Preisen. Auftragsnotizen werden ebenfalls angezeigt.
Auch dieses zweite Script kommt mit der Python-Standardbibliothek aus, es braucht kein Framework und keine Installation. Das vollständige Script plenty_search.py liegt ebenfalls im Repository auf Codeberg.
Idee zur Weiterentwicklung: Die Performance bei der Volltext-Suche kann mit einer Extension wie FTS5 verbessert werden. Wer Lust hat, daran mitzuarbeiten, findet das Script im Repository – über Anregungen oder Beiträge freue ich mich.
Lehren für andere Migrationen
Bei einem Systemwechsel lohnt sich der Blick in den Backup-Bereich des alten Systems. Der Datenbank-Dump ist oft vollständiger und einfacher zugänglich als das, was über die offiziellen Exporte herauskommt. Mit etwas Aufbereitung bleiben die eigenen Daten als lokales Archiv durchsuchbar, und das neue System startet sauber, ohne Altlasten.
Du planst einen Systemwechsel – ein neues ERP, einen neuen Shop – und willst deine Daten dabei sauber sichern? Melde dich gerne für einen unverbindlichen Beratungstermin.
